Abstract
Many real-world data science tasks involve complex web-based interactions: finding appropriate data available on the internet, synthesizing multimodal data from different locations, and producing summarized analyses. Existing web benchmarks often focus on simplistic interactions and often do not require diverse tool-using capabilities. Conversely, traditional data science benchmarks typically concentrate on static, highly structured datasets and do not assess end-to-end workflows that encompass data acquisition, cleaning, analysis, and insight generation. In response, we introduce WebDS, the first end-to-end web-based data science benchmark. It comprises 870 web-based data science tasks across 29 diverse websites from structured government data portals to unstructured news media, challenging agents to perform complex, multi-step, tool-based operations, across heterogeneous data formats, to better reflect the realities of modern data analytics. Evaluations of current SOTA LLM agents indicate significant performance gaps in accomplishing these tasks. For instance, Browser Use, which accomplishes 80% of tasks on WebVoyager, completes only 15% of tasks in WebDS, which our analysis suggests is due to new failure modes, such as poor information grounding, repetitive behavior and shortcut-taking that agents performing WebDS's tasks display. By contrast, humans achieve around 90% accuracy, highlighting a substantial gap between current agents and human performance. By providing a more robust and realistic testing ground, WebDS sets the stage for significant advances in the development of practically useful LLM-based data science.
Example Task
WebDS tasks begin with autonomous web browsing for relevant data, followed by analysis and/or visualization, and culminate in a well-reasoned, context-aware output. The example below illustrates a multi-site task where an agent must navigate a university data portal, cross-reference national demographic sources, and produce a report.

Dataset Statistics
WebDS consists of 870 human-written tasks spanning 29 data-rich websites grouped into 10 high-stakes domains. Every task is manually labeled with one or more of seven attributes and categorized into easy, medium, or hard difficulty based on its structural and content properties.
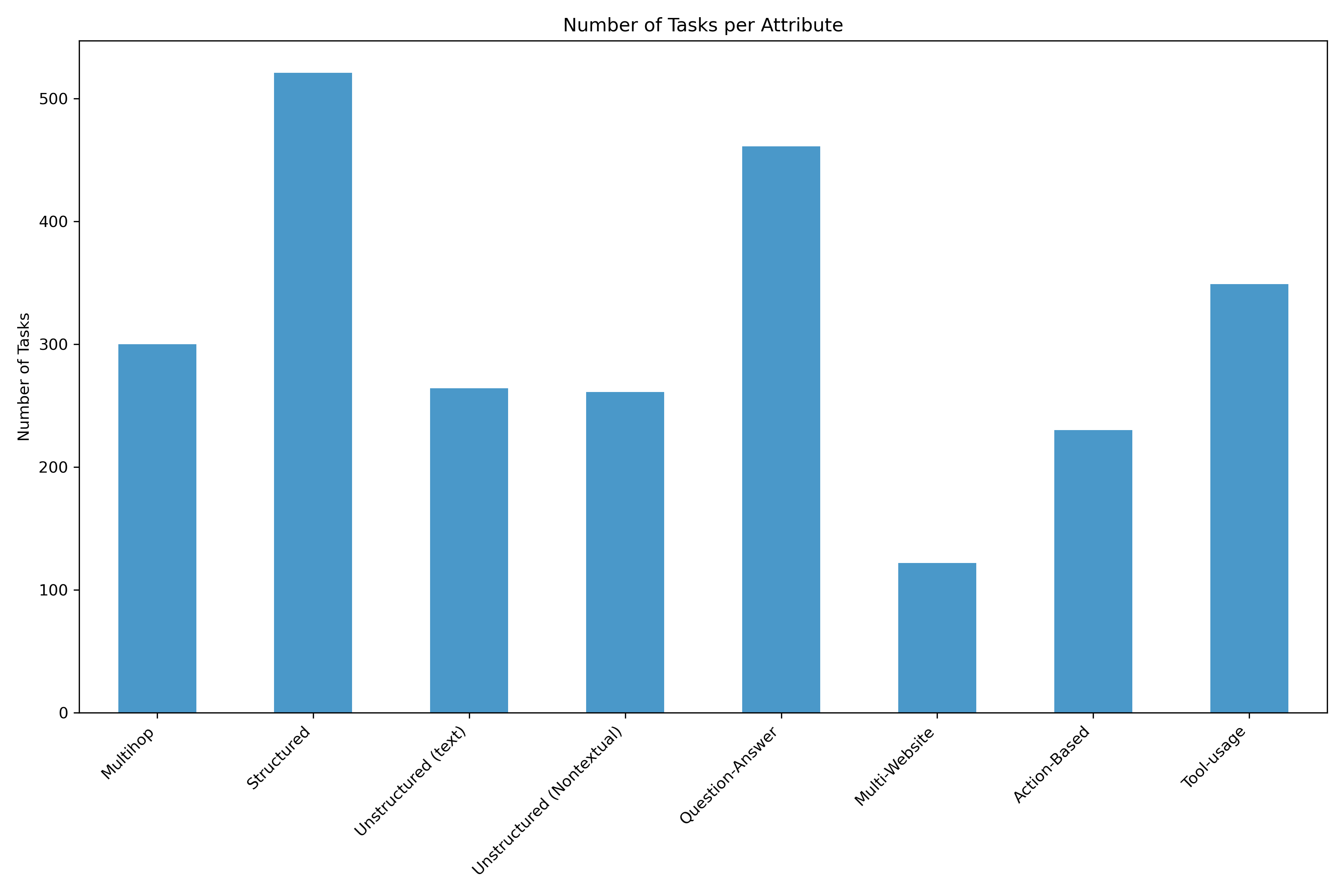
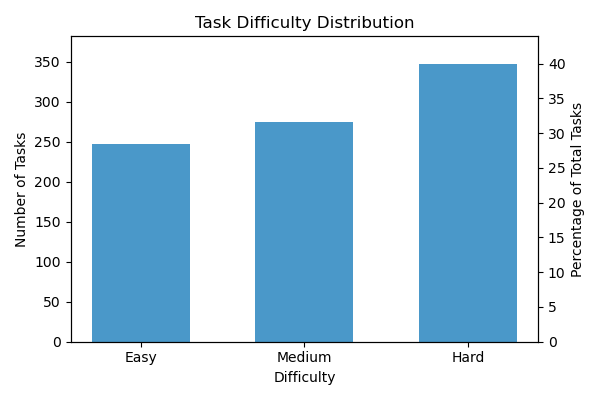
Domains & Websites
| Domain | Websites |
|---|---|
| Economics / Markets | BEA, FRED, St Louis FED, Trading Economics, DataUSA |
| Demographics | WorldPop, Worldometer |
| Music | Tunebat, MusicBrainz, RIAA, Richard Powers |
| Tourism, Trade & Airlines | UNWTO, IATA |
| Higher Education | MIT, UChicago |
| Scientific Research | arXiv |
| Sports | Understat |
| Government & Public Policy | CFPB, Our World in Data, Reddit |
| Energy & Climate | Climate.gov, NOAA |
| Health | CDC Mental Health, CDC COVID, CDC Obesity, NIH |
| E-Commerce | Shopping, Stocknear |
Benchmark Comparison
WebDS is the only benchmark that spans all eight task dimensions—multihop reasoning, structured and unstructured data, web navigation, QA, multi-site integration, actions, and tool use.
| Dataset | Multihop | Structured | Unstructured | Web Nav | QA | Multisite | Actions | Tool-Use |
|---|---|---|---|---|---|---|---|---|
| SQuAD | × | × | ✓ | × | × | × | × | × |
| WikiTableQ | ✓ | ✓ | × | × | × | × | × | × |
| HotpotQA | ✓ | × | ✓ | × | × | × | × | × |
| WebVoyager | × | × | × | ✓ | ✓ | × | ✓ | × |
| WebArena | ✓ | × | × | ✓ | ✓ | ✓ | ✓ | ✓ |
| GAIA | ✓ | × | ✓ | ✓ | ✓ | ✓ | × | × |
| WebWalker | ✓ | × | ✓ | ✓ | ✓ | ✓ | × | × |
| AssistantBench | ✓ | × | ✓ | ✓ | ✓ | × | ✓ | ✓ |
| WebDS (ours) | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
Leaderboard
Success Rate (SR %) and LLM-judged score (1–5) of 10 agents on WebDS-live. Success is determined by a binary SUCCESS/UNSUCCESS judgment; the score is a 1–5 integer from an LLM judge that evaluates the full trajectory. Human performance on the same protocol is ~90%.
| # | Agent | Overall | Easy | Medium | Hard |
|---|
If only the model name is specified, the model is run on the base WebArena agent framework. BrowserUse and AgentOccam rows use their native frameworks with the adaptations described in the paper.
Citation
@inproceedings{hsu2026webds,
title = {WebDS: An End-to-End Benchmark for Web-based Data Science},
author = {Hsu, Ethan and Yam, Hong Meng and Bouissou, Ines and Murali John, Aaron
and Thota, Raj and Koe, Josh and Putta, Vivek Sarath and Dharesan, G K
and Spangher, Alexander and Murty, Shikhar and Huang, Tenghao
and Manning, Christopher D.},
booktitle = {International Conference on Learning Representations (ICLR)},
year = {2026},
url = {https://arxiv.org/abs/2508.01222}
}